Thursday, 25 June 2015
Analisis Web
Analisis Web

Analisis Web / Pengukuran Web adalah pengukuran,
pengumpulan, analisis dan pelaporan data internet untuk tujuan memahami dan
mengoptimalkan penggunaan web. Untuk menganalisa suatu website perlu di ketahui
kriteria apa saja yang akan di analisa.
Tools Analisis Web
Kita perlu analisa website atau blog dengan layanan
online untuk memeriksa detail informasi “accessibility” dari website/blog anda.
Dibawah ini, ada 8 Tool Analisa Web yang dapat membantu anda untuk analisis
website dengan memberikan informasi detail dari segi “accessibility” dan
desain. Semua tool online dibawah ini, gratis dan sangat mudah untuk digunakan
:
1.
Color Blindness Simulator
Colour
Blindness Simulator, dapat membantu anda untuk memeriksa bagaimana aspek gambar
dan pewarnaan (color) dari website/blog. Anda juga dapat dengan cepat upload
file gambar (JPEG) dengan resolusi 1000x1000px dan analisa aspek
pewarnaan halaman website anda.
2.
Juicy Studios Image Analyzer
Dengan
tool online ini, kita dapat menganalisa masalah setiap gambar yang ada pada
halaman website. Tool ini juga, dapat menginformasikan detail informasi width,
height, alt, dan longdesc, makanya tool website - Image Analyzer merupakan
salah satu tool analisa website terbaik.
3.
Firefox Accessibility Extension
Jika
anda termasuk pengguna web browser Firefox, maka Add-ons Friefox ini sangat
penting karena dengan Add-ons ini, anda dapat aktifkan setiap element desain
dari halaman website. Anda dapat dengan cepat buat daftar gambar dan element
yang lain. Add-ons ini juga disertakan dengan standar validasi “W3C HTML
Validator” .
4.
Test and Improve Readability
Tool
Online gratis dengan fitur untuk testing dan meningkatkan konten website anda.
5.
LinkPatch
“Broken
link” membuat halaman webstie.blog dan yang lain menjadi tidak dapat
diakses, hal ini adalah yang terpenting selain faktor SEO, tapi dengan tool
seperti LinkPatch, untuk cek “broken link” dari semua URL yang anda inginkan.
Dengan LinkPatch, anda dapat install kode tracking dalam hitungan detik
dengan fitur monitoring.
6.
WAVE
WAVE
merupakan tool interaktif yang menunjukkan tingkat kunjungan dari website
dengan 3 cara yang berbeda: “Errors, Features, and Alerts”, “Structure/Order”,
dan Text-Only”.
7.
AccessColor
Tes
AccessColor kontras warna dan “color brightness” antara bagian depan dan
belakang dari semua element DOM. AccessColor akan menemukan kombinasi warna
yang relevan dengan dokumen HTML dan CSS.
8.
aDesigner
aDesigner
adalah simulator yang membantu desainer untuk memastikan konten dan aplikasinya
diakses. aDesigner juga membantu user untuk cek aksesbility dokumen ODF dan
Flash.
Parameter Pengukuran Web
Salah satu teknik mengukur dan menguji suatu kinerja web
adalah dengan mengukur pengalaman seseorang atau user experience pengunjung
situs yang berinteraksi dengan halaman-halaman web yang berada di internet
(Keynote System, Inc 2010).
Kinerja suatu web atau web performance sangat dipengaruhi
oleh beberapa komponen-komponen dasar yang dibagi menjadi dua bagian penting,
yaitu (1) dilihat dari gambaran transaksi web atau perspective transaction dan
(2) gambaran komponen aplikasi atau application component perspective (Keynote
System, Inc 2010). Transaksi web atau web transaction lebih menitikberatkan
pada sisi pengalaman pengguna atau user experience sedangkan komponen aplikasi
lebih menitikberatkan pada komponen jaringan komputer atau computer network.
Pengalaman Pengguna (User experience), diantaranya adalah
(Keynote System, Inc 2010) :
·
Time to opening page (time_to_opening_page), maksudnya adalah mengukur, dari
sisi pengguna, waktu yang dibutuhkan pada saat pertama kali membuka halaman
web. Waktu dimulai dari aksi pertama setelah internet agent memutuskan untuk
berpindah ke halaman berikutnya. Waktu berakhir ketika pesan opening page
ditampilkan di Web browser status bar.
·
Page download (page_download_time), maksudnya adalah waktu yang dibutuhkan
antara ketika Web browser membuat sinyal opening page dan ketika Web browser
akan menampilkan pesan done di status bar.
Komponen Jaringan
Komponen jaringan (network component) adalah salah satu
hal yang mempengaruhi kinerja web. Beberapa komponen jaringan tersebut
diantaranya adalah (Keynote System, Inc 2010):
Ø DNS lookup (DNS_time), komponen ini berfungsi
untuk menghitung waktu yang dibutuhkan untuk menterjemahkan host name (contoh,
www.keynote.com) menjadi IP address (contoh, 206.79.179.108).
Ø Initial connection (initial_connection),
komponen ini mengukur waktu pulang pergi atau round-trip time (ukuran waktu
yang dibutuhkan jaringan untuk melakukan perjalanan dari host sumber menuju
host tujuan dan kembali lagi ke host sumber) koneksi jaringan antara browser
dan server.
Ø Request time (request_time), adalah jumlah
waktu yang dibutuhkan oleh web browser untuk mengirim permintaan (request) ke
internet.
Ø Client time (client_time), adalah jumlah
waktu untuk mengunduh elemen halaman web selama data dihantarkan.
Ø Total measurement time (measurement_network),
adalah jumlah waktu untuk mengunduh halaman web dilihat dari sudut pandang
jaringan.
Disini saya akan membahas "Piwik Web Analytics"
Plugin ini memberikan Piwik Web Analytics data dalam pimcore menggunakan API Piwik itu. Ini terintegrasi di pimcore itu Laporan & Pemasaran kompleks. Hanya memberikan mandat API untuk instalasi Piwik Anda dalam Laporan & pengaturan Marketings (tab "Piwik").
Saat ini fitur ini diimplementasikan:
• trackercode outputfilter yang menambahkan javascript neccessary ke kepala html itu
• portlet untuk menyambut halaman
• portlet untuk top 10 halaman
• Laporan keseluruhan
• Laporan untuk setiap halaman
• Laporan global untuk Qr-kode
Disini saya akan membahas "Piwik Web Analytics"
Plugin ini memberikan Piwik Web Analytics data dalam pimcore menggunakan API Piwik itu. Ini terintegrasi di pimcore itu Laporan & Pemasaran kompleks. Hanya memberikan mandat API untuk instalasi Piwik Anda dalam Laporan & pengaturan Marketings (tab "Piwik").
Saat ini fitur ini diimplementasikan:
• trackercode outputfilter yang menambahkan javascript neccessary ke kepala html itu
• portlet untuk menyambut halaman
• portlet untuk top 10 halaman
• Laporan keseluruhan
• Laporan untuk setiap halaman
• Laporan global untuk Qr-kode
Crawler

Crawler adalah sebuah program/script otomatis yang
memproses halaman web. Sering juga disebut dengan web spider atau web robot.
Ide dasarnya sederhana dan mirip dengan saat anda menjelajahi halaman website
secara manual dengan menggunakan browser. Bermula pada point awal berupa sebuah
link alamat website dan dibuka pada browser, lalu browser melakukan request dan
men-download data dari web server melalui protokol HTTP.
Setiap Hyperlink yang ditemui pada konten yang tampil
akan dibuka lagi pada windows/tab browser yang baru, demikian proses terus
berulang. Nah sebuah web crawler mengotomatisasikan pekerjaan itu.
Kesimpulannya,
dua fungsi utama web crawler adalah:
1.
Mengidentifikasikan Hyperlink.
Hyperlink
yang ditemui pada konten akan ditambahkan pada daftar visit, disebut juga
dengan istilah frontier.
2.
Melakukan proses kunjungan/visit secara rekursif.
Dari
setiap hyperlink, Web crawler akan menjelajahinya dan melakukan proses
berulang, dengan ketentuan yang disesuaikan dengan keperluan
aplikasi.
Cara
kerja Crawler
Cara kerja Crawler , pertama robot mengumpulkan informasi
pada halaman blog/web dan semua media internet yg bisa diindeks oleh search
engine. Robot tersebut kemudian membawa informasi yg didapatnya ke data center.
Di data center, data tersebut kemudian di oleh sedemikian rupa, apabila
memenuhi persyaratan, maka dia akan dimasukkan ke dalam indeks. Nah, proses yg
dilakukan oleh user search engine adalah memanggil indeks-indeks tersebut,
apabila indeks2 memiliki kesesuaian dengan yg dicari user (dan bila memiliki
peringkat yg baik), di akan ditampilkan di halaman utama search engine
(berperingkat).
Cara
agar website/blog masuk dalam Crawler itu ada dua,
Pertama
: Membuat sitemap dan atau daftar isi
Sitemap (peta situs) blog berfungsi membantu search
engine bot menjelajahi, menemukan dan mengindeks konten blog kita. Jika blog
anda berplatform wordpress.org, cara paling mudah membuat sitemap adalah dengan
memasang plugin bernama Google XML sitemaps. Sitemap sebenarnya hampir sama
dengan halaman daftar isi yang sering kita buat di blog, hanya sitemap berisi
kode-kode HTML yang dibaca oleh bot sedangkan daftar isi untuk dibaca oleh
manusia. Jika anda ingin sitemap yang juga berfungsi sebagai daftar isi, gunakan
plugin bernama Dagon Sitemap Generator. Beberapa themes seperti GoBlog Themes
sudah menyediakan sitemap secara default seperti ini: Sitemap.
Kedua
: Mendaftarkan sitemap di Google Webmaster Tools
Sitemap blog anda perlu didaftarkan di Google Webmaster
Tools. Google webmaster sendiri penting diikuti oleh semua pemilik blog agar
anda dapat menganalisa semua data yang berkenaan dengan blog anda. Melalui uji
sitemap, kita bisa mengetahui konten mana di blog yang belum terindeks Google.
Daftarkan dulu blog anda di Google Webmaster Tools.
Berikut
ini adalah contoh-contoh dari Crawler:
1.Teleport
Pro
Salah satu software web crawler untuk keperluan offline
browsing. Software ini sudah cukup lama popular, terutama pada saat koneksi
internet tidak semudah dan secepat sekarang. Software ini berbayar dan
beralamatkan di http://www.tenmax.com.
2.HTTrack
Ditulis dengan menggunakan C, seperti juga Teleport Pro,
HTTrack merupakan software yang dapat mendownload konten website menjadi sebuah
mirror pada harddisk anda, agar dapat dilihat secara offline. Yang menarik
software ini free dan dapat di download pada website resminya di
http://www.httrack.com
3.Googlebot
Merupakan web crawler untuk membangun index pencarian
yang digunakan oleh search engine Google. Kalau website anda ditemukan orang
melalui Google, bisa jadi itu merupakan jasa dari Googlebot. Walau
konsekuensinya, sebagian bandwidth anda akan tersita karena proses crawling
ini.
4.Yahoo!Slurp
Kalau Googlebot adalah web crawler andalan Google, maka
search engine Yahoo mengandalkan Yahoo!Slurp. Teknologinya dikembangkan oleh
Inktomi Corporation yang diakuisisi oleh Yahoo!.
5.YaCy
Sedikit berbeda dengan web crawler lainnya di atas,
YaCy dibangun atas prinsip jaringan P2P (peer-to-peer), di develop dengan
menggunakan java, dan didistribusikan pada beberapa ratus mesin computer
(disebut YaCy peers). Tiap-tiap peer di share dengan prinsip P2P untuk berbagi
index, sehingga tidak memerlukan server central.
Contoh
search engine yang menggunakan YaCy adalah Sciencenet (http://sciencenet.fzk.de)
untuk pencarian dokumen di bidang sains.
Search Engine

Search engine adalah istilah atau penyebutan bagi website
yang berfungsi sebagai mesin pencari, mesin pencari ini akan menampilkan
informasi berdasarkan permintaan dari user pencari konten, konten yang
ditampilkan adalah konten yang memang sudah terindex dan tersimpan di database
server search engine-nya itu sendiri.
Saat ini sudah mulai banyak website search engine, namun
dari sekian banyak search engine yang ada saat ini berikut ini beberapa search
engine yang terbilang popular, seperti Yahoo!, Alltheweb, MSN, AskJeeves,
Google, AltaVista, dan Lycos.
Yahoo!
(http://www.yahoo.com)
Salah satu portal terbesar di Internet, selain MSN., dan
juga salah satu mesin pencaru tertua. Halaman utamanya sendiri tidak terlalu
ramah untuk pencarian, tetapi Yahoo! menyediakan search.yahoo.com untuk itu.
Yahoo! menggunakan jasa Google untuk mencari informasi di web, ditambah dengan
informasi dari databasenya sendiri. Kelebihan Yahoo! adalah direktorinya.
Yahoo! juga menyediakan pencarian yellow pages dan peta, yang masih terbatas
pada Amerika Serikat. Yahoo juga menyediakan pencarian gambar.
Alltheweb
(http://www.alltheweb.com)
Keunggulan Alltheweb adalah pencarian file pada FTP
Server. Tidak seperti web, FTP adalah teknologi internet yang ditujukan untuk
menyimpan dan mendistribusikan file, biasanya program, audio atau video. Web
sebenarnya lebih ditujukan untuk teks. Sejauh ini, hanya AllTheWeb yang
menyediakan jasa pencarian file.
MSN
(http://search.msn.com)
Mesin pencari dari Microsoft Network ini menawarkan
pencarian baik dengan kata kunci maupun dari direktori. Pemakai Internet
Explorer kemungkinan besar sudah pernah menggunakan mesin pencari ini. Situs
Searchenginewatch mencatat MSN sebagai mesin pencari ketiga populer setelah
Google dan Yahoo! Tak ada pencarian image, atau news. Menyediakan pencarian
peta, yellow pages, white pages, pencarian pekerjaan, rumah.
AskJeeves
(http://www.ask.com)
Situs mesin pencari yang satu ini mengunggulkan
kemampuannya untuk memahami bahasa manusia. Pengguna bisa menggunakan kalimat
lengkap, bukan kata kunci. Situs ini berguna untuk mengetahui jawaban dari pertanyaan(misal:
when did world war II end?).
Google
(http://www.google.com)
Selain pencarian web, Google juga menyediakan jasa
pencarian gambar, pencarian ?berita serta pencarian pada arsip USENET
(newsgroup), serta direktori, seperti Yahoo! Kelemahannya terletak pada tidak
tersedianya pencarian file, video, dan audio. Keunggulan Google terutama adalah
pada pencarian teks, terutama dari algoritma PageRank, database-nya yang besar
serta banyaknya jenis file yang diindeksnya.
AltaVista
(http://www.altavista.com)
Satu saat, AltaVista pernah menjadi mesin pencari
terbesar. Saat ini, selain Alltheweb, Altavista juga menawarkan pencarian audio
dan video. Keunggulan AltaVista adalah pilihan pencarian yang paling lengkap di
antara semua mesin pencari.
Lycos
(http://www.lycos.com)
Salah satu mesin pencari tertua. Saat ini Lycos lebih
dikenal sebagai portal, sehingga fungsi pencarinya tidak terlalu menonjol.
Lycos, selain mendukung pencarian web, juga menyediakan pencarian file MP3, dan
video pada http://multimedia.lycos.com.
Perbedaan
Search Engine Yang Ada
Ada banyak sekali contoh perbedaan search engine, disini
hanya akan ada beberapa yang saya jelaskan. Sebagai contoh, untuk Yahoo! dan
Bing, On Page Keyword merupakan faktor yang paling penting, sedangkan untuk
Google, Link-lah yang merupakan faktor yang sangat penting.
Selain itu, halaman website untuk Google adalah seperti
wine – semakin tua umurnya, semakin bagus peringkatnya. Sedangkan untuk Yahoo!
biasanya tidak mementingkan hal tersebut. Maka dari itulah, anda memerlukan
waktu yang lebih banyak untuk membuat website anda matang untuk berada di
peringkat atas di Google, daripada di Yahoo!.
Kerja
Sebuah Search Engine
Jika anda ingin mencari sesuatu,tentunya telah memiliki
sebuah kata kunci ( keyword ) untuk sesuatu yang anda cari.Sebuah search engine
bekerja dengan menerima kata kunci dari pengguna,memproses dan menampilkan
hasilnya.Akan lebih mudah dibayangkan jika anda terbiasa melakukan pemrograman
data base dengan menggunakan Query atau SQL,karena tentunya anda telah terbiasa
menampilkan data pada table-table dengan kriteria tertentu.Tapi,Web Search
Engine yang tersedia saat ini telah memiliki kemampuan yang lebih baik dalam
menerima dan mengolah keyword dari pengguna.
Bagaimana search engine menampilkan informasi dari gudang
data yang sedemikian besar dalam waktu yang singkat..? Sebagaiman juga dengan
pemrograman database,menggunakan indeks adalah salah satu cara ampuh untuk
meningkatkanperforma kecepatan.Pencarian juga sudah tidak terbatas pada
pencarian dokumen,tetapi sangat variatif tergantung pada kebutuhan anda.Anda
dapat mencari gambar,musik,software, atau dokumen dengan fornat tertentu.
Hal lain yang tidak kalah penting bagaiman search engine
( terutama web search engine ) mengumpilkan semua data tersebut .Jangan kaget
jika anda cukup aktif menulis pada forum.blog,mailing list atau mungkin sebagai
spammer maka search engine dapat menampilkan ke seluruh dunia.Search engine
mampu menemukan tulisan anda karena adanya metode pengambilan informasi (
Informatio Retrival/IR ) yang mencari metadata dan database yang tersebar di
internet.Sebagai contoh,pada saat anda mengetikkan sebuah komentar pahit pada
seseorang dan melakukan submit pada sebuah halaman website,halaman web yang
berisi komentar anda telah tersedia bagi aplikasi-aplikasi IR untuk dibaca
siapa saja yang melakukan pencarian dengan keyword yang tepat.
Web Archive
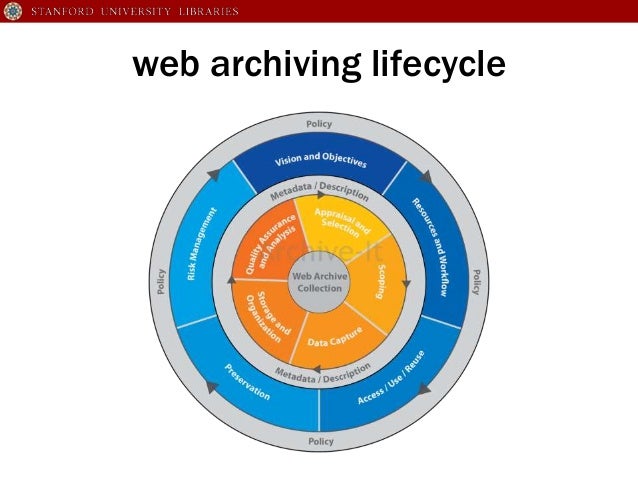
Web Archive adalah Sebuah file format terkompresi,
didefinisikan oleh Java EE standar, untuk menyimpan semua sumber daya yang
diperlukan untuk menginstal dan menjalankan aplikasi Web dalam satu file.
Cara
Kerja Web Archiving
Yang paling umum web pengarsipan teknik menggunakan web
crawler untuk mengotomatisasi proses pengumpulan halaman web. Web crawler
biasanya mengakses halaman web dengan cara yang sama dengan yang dilakukan user
yang menggunakan web browser untuk menemukan website yang ingin dicari.
Contoh
Web Archive
Local
Website Archive
Aplikasi inilah yang memampukan kamu dapat dengan cepat
untuk menyimpan dan mengarsipkan secara lengkap halaman web, disertai dengan
keseluruhan gambar untuk tujuan digunakan sebagai referensi. Kamu dapat
mengorganisasir arsip halaman web ke dalam kategori-kategori yang relevan atau
sejenis, dan dapat menggunakan built-in browser display untuk menampilkannya
secara offline.
Sebagai tambahan, kamu juga dapat melakukan pencarian
keseluruhan halaman web yang tersimpan melalui penggunaan keyword, serta dapat
melakukan ekspor secara keseluruhan ataupun beberapa item saja yang terseleksi
ke dalam sebuah file executable selfextracting. File tersebutlah yang dapat
digunakan untuk mengirimkan koleksi-koleksi kamu tersebut kepada teman, ataupun
melakukan transfer ke sebuah komputer berbeda.
Sumber :
http://lintartamara.blogspot.com/2013/04/analisis-web-pengukuran-web-crawler.html
http://bie-wellca.blogspot.com/2013/04/pengukuran-web-crawler-search-engine.html
http://www.bum1.info/2012/03/web-crawler.html
http://www.ihsanfirdaus.com/search-engine/
Subscribe to:
Post Comments
(
Atom
)



No comments :
Post a Comment